Search powered by Funnelback
If you’ve used a search interface any time in the past 5 years, you’ve probably seen query completion in action.
At first, it may have seemed magical - the search engine knows what you’re looking for, after a single keystroke, and helpfully suggests a range of concepts that begin with the word you’ve started typing.
Modern (and not-so-modern) word processors and text editors have had a similar capability for several years, but have usually limited themselves to suggesting single words drawn from a fixed dictionary or, in the case of a code IDE, pre-existing variables, methods or code libraries.
"Well, give me a Y, give me a… Hey! All I have to type is Y. … I just tripled my productivity!"
Homer Simpson, typing ‘yes’ on his computer (King Size Homer)
As a user, the benefits seem obvious, even if the underlying mechanisms and biases inherent in such a system are not. As a content manager and search administrator, we can explore several methods to control and influence this now-expected behaviour during query formulation to further our own agenda.
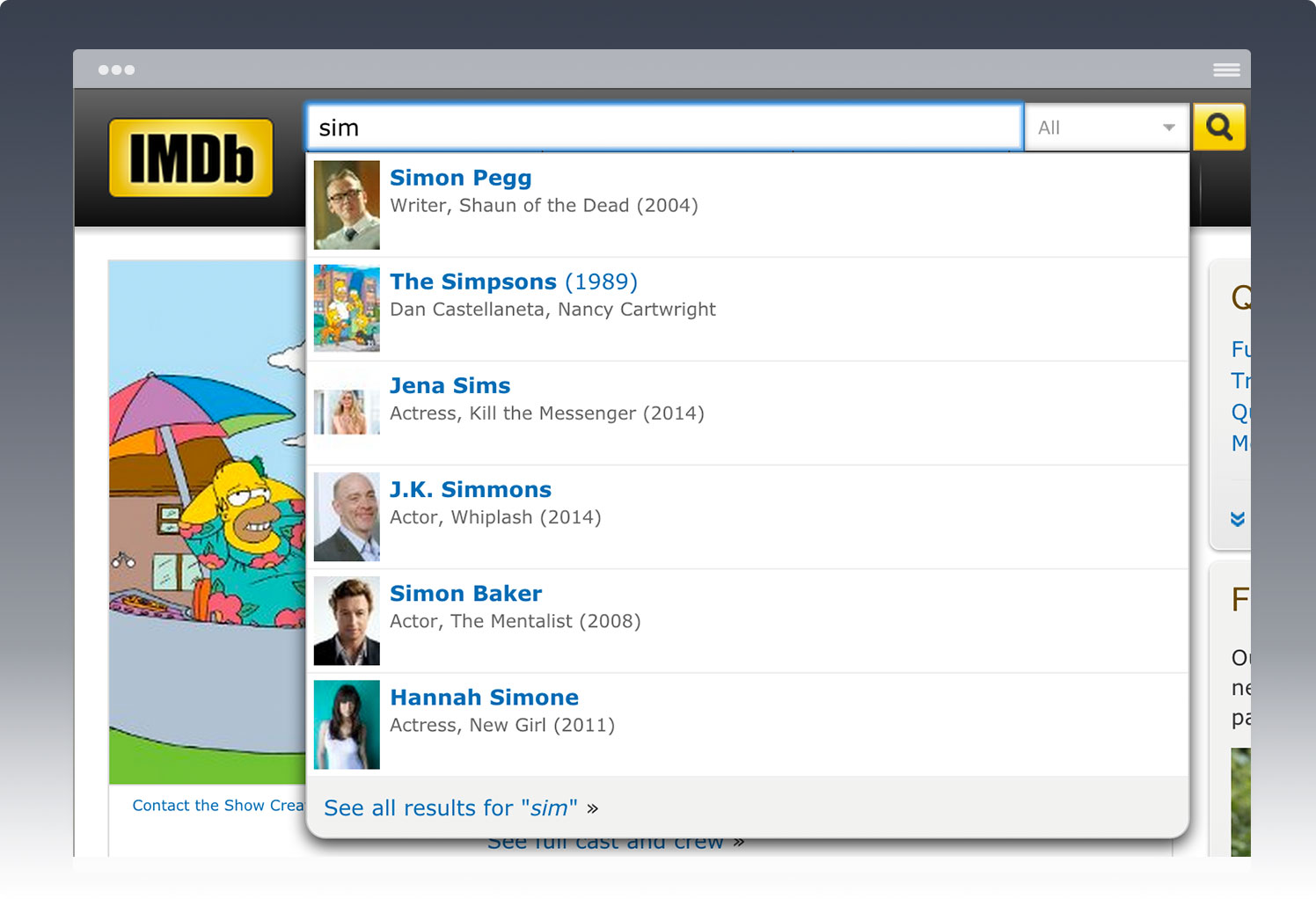
Usage Scenarios
A considerate search interface designer recognises that accidents happen; people mis-spell, mis-type and are frequently distracted. Minimising the amount of high-focus, high-accuracy input from an imperfect, hurried human required for a ‘perfect’ search result to be produced, is the broader goal we’re aiming to solve. Simultaneously, we’re wanting to steer users down a path likely to be of benefit to them, as well as our content authors or product owners.
"To obtain a special dialling wand, please mash the keypad with your palm now."
Automated phone message from the Springfield nuclear power plant (King Size Homer)
The ‘dialling wand’ problem could be extended to include scenarios where the user is in a suboptimal environment for keyboard-based entry, i.e. anywhere they may be moving, using an on-screen keyboard, anywhere the light is unpredictable, or where small children, animals or other distractions are nearby.
Auto-complete, auto-suggest, auto-refine, typeahead - what's the difference?
At first glance, these terms appear synonymous, but it’s worth understanding the differences inherent in each approach, and how users are likely to interact with each approach. We’ll also look at real-world examples to compare and contrast.
Search auto-complete
As a baseline, whole-of-web search engines have the widest range of use cases and content to cover, so the simplest UI is the safest starting point for them during the query formulation phase, with the search engine aiming to automatically *complete* the search query we’ve partially entered.
Visiting google.com on a desktop browser as an anonymous user and starting a search for ‘meta’ presents us with the following auto-completion:
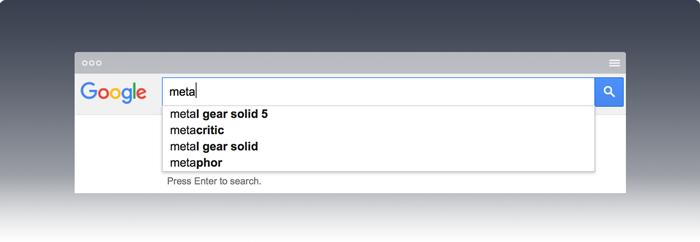
Note:
- My target term ‘metadata’ isn’t present (yet).
- All auto-complete terms *start* with the partial query ‘meta'.
- Many of the suggested terms are topical (‘Metal Gear Solid 5’ is a big-budget video game released on September 2015).
- Only a small number of suggestions are present.
The action performed when the user clicks on an item in the auto-completion list is “go and produce a list of search results for that suggestion”.
Search auto-refine
With a more targeted set of content, and with a smaller set of user tasks to support, users can benefit from refinement options appearing during the query formulation phase. These refinements can then aid disambiguation whilst clarifying intent.
In practice, these may consist of:
- Term + category (e.g. ‘nik’ > ’nikon in Digital Cameras’).
- Shortcut to faceted search (e.g. ‘kin’ > ’Department: Kindle Hardware’).
Consider an anonymous search on Amazon.com using the partial query ‘nik’ - ‘Nike’ is an obvious term to auto-complete. This term could can then be used to refine which of the thousands of potential departments a user may intend to browse further.
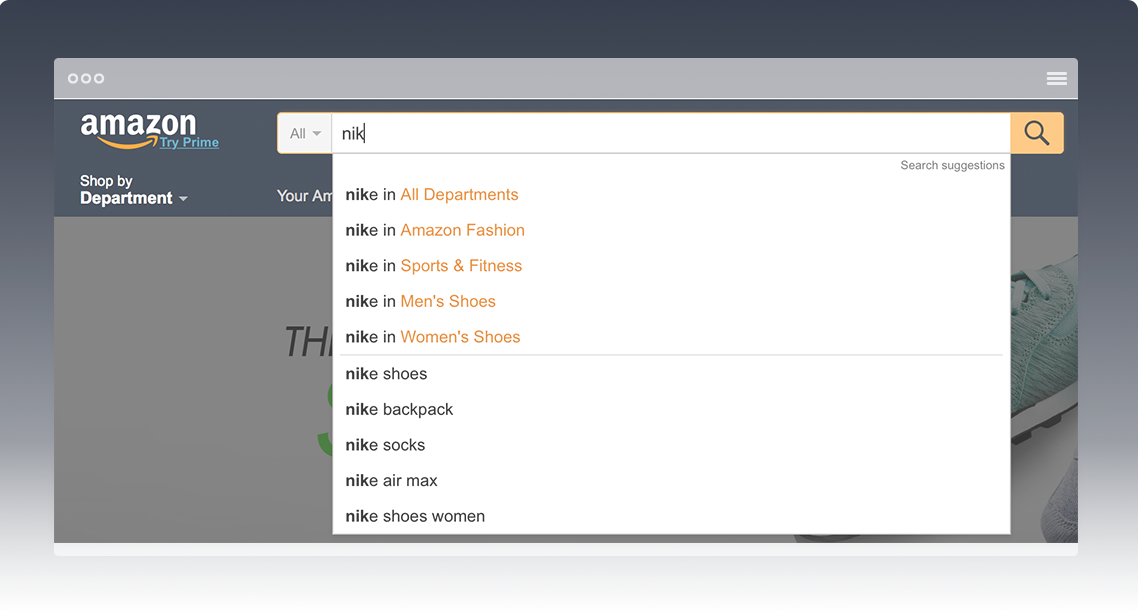
The actions available to be performed vary: either the search term is submitted directly to the search engine, or the search term plus the refinements are submitted. In both cases, a list of results appears
Note:
- My target term ‘nikon’ isn’t present (yet).
- My starting context is broad (‘All Departments’), but selecting a department prior to typing produces a tighter list of completed terms and auto-refinements.
- A mixture of pre-canned refinements and completions is provided, with the refinements applied to the most-likely completion term (‘nike’).
- Refinements outside the current department are suggested as a last resort.
Search auto-suggest
If you’ve got a smaller set of products or pages to work with, you may want to attempt to bypass a search results page entirely, and automatically suggest a product or page that closely matches a user’s partial query.
Entities worth considering for auto-suggestion:
- Products
- People
- Places
- Organizations
Even with the enormous number of pages residing in the English Wikipedia, a search for the partial query ‘lex’ suggests a reasonable group of specific pages.
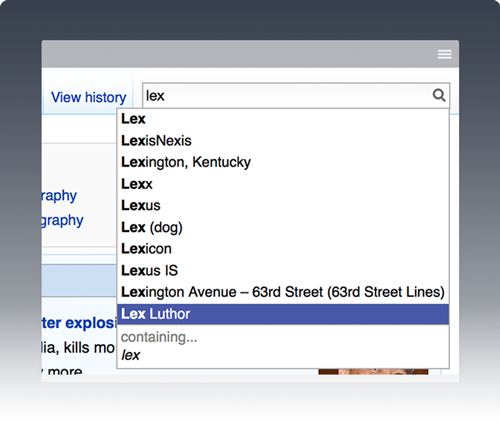
Note:
- My target term ‘lexicon’ is present.
- All auto-suggest terms begin with the partial term (although Wikipedia also suggests ‘Luthor, Lex’ when searching for the partial query ‘lutho', incorporating the site’s redirected pages in the list of candidate suggestions).
- No more than 10 suggested items appear.
- Sort order appears to align with page popularity.
- Users can still search for pages containing the partial query ‘lex’.
Where appropriate, additional details may be displayed alongside the suggested items (e.g. thumbnails, prices, categories), in order to give users a stronger impression of the detail lying beneath the item suggested.
The action performed when the user clicks on an item in the auto-suggestion list is ‘go directly to that suggested page/product’.
Search typeahead / tap-ahead
When screen real estate is at a premium, and keyboard input is even more cumbersome than usual, mobile-based auto-completion mechanisms encourage a dual-action approach.
Using the ebay mobile app on iOS and searching for ‘por' produces:
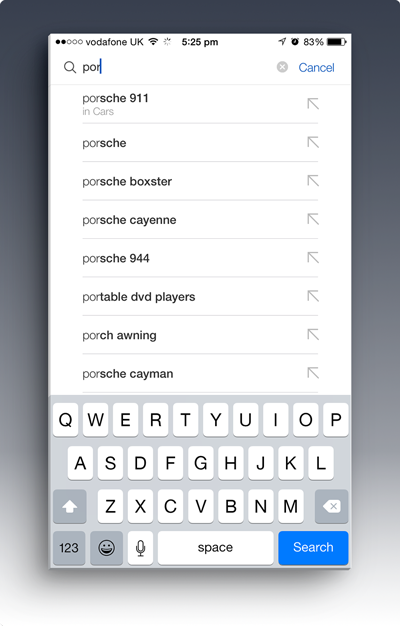
Noting the upper-left pointing arrow on the far-right of each auto-completion term, tapping that arrow (instead of the word) fills the search input box with that term, then creates a new list of completion candidates:
- Keyboard tap: ‘j’
john
java
javinda
- Tap-ahead: ‘john’
john smith
john jones
- Tap-ahead: ‘john smith’
john smith resigns
john smith announces
- Completion tap: ‘john smith resigns’
In this example, a user has been able to submit a very specific search query through only four taps on their touch-based device.
Mixing and matching options
Combining approaches is also feasible - ensure you’re clearly conveying to users what the likely action is behind each suggestion/completion/refinement via the UI.
If you’ve only got space for ten items to appear below your input box, consider a mix of completions and suggestions, as seen at twitter.com and linkedin.com.
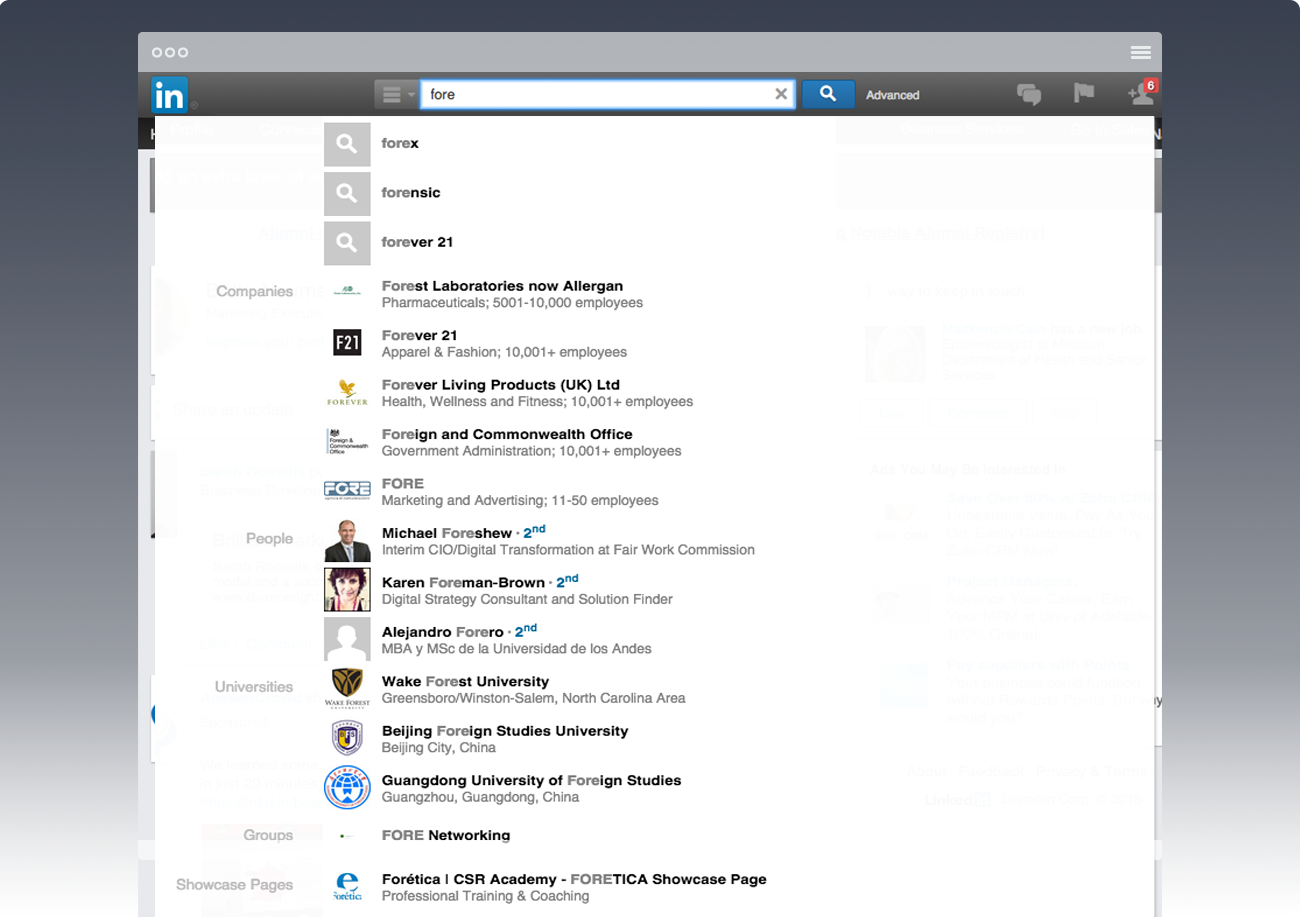
If search is front-and-center of your home page, you may also want to consider several channels of suggestion, mixing in search history with completions, several tiers of suggestions and some refinements.
In all cases, though, try not to prevent users from simply submitting their search term as typed, however incomplete or ambiguous it may be.
Sourcing suggestions
Knowing what to display is part of the problem - potential data sources to drive your fancy new search UI might include:
Unstructured Content
Within certain size and frequency thresholds, any word appearing in the content gathered by the search engine could be a candidate for auto-completions. Weighting by term frequency would be a good starting point.
Structured Content
Consider your high-value content - the items that your internal audiences are competing to place on your home page. With a single keystroke (or two), these items can be summarised and placed in front of users within a global site or enterprise search during query formulation, potentially bypassing search results pages entirely.
Triggering and weighting of structured content items in query completion can also be subject to specific rules: users performing a known-item search for something like an ISBN or ticket number may have the suggestions triggered by those numbers, but the book or ticket title is given greater prominence in the suggestion list instead.
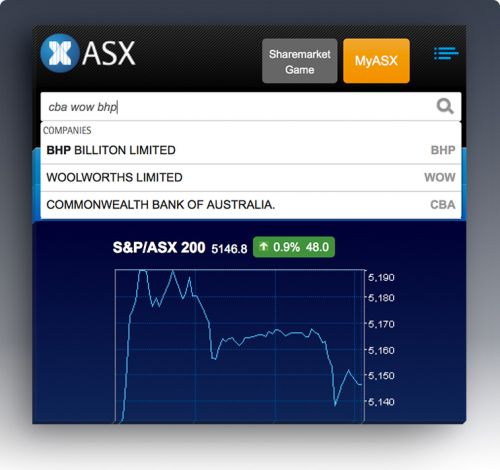
Even if you’re starting with unstructured content, you may be able to tap into entity extraction filters to automatically refine content containing a particular entity type (e.g. ‘jav’ automatically suggests refinements like: ‘Location: Java’ or ‘Person: Javinda Smith’ in addition to ‘java’, ‘javanese’, ‘javelin’ and ‘javinda’).
Search History
While these won’t necessarily be available at the launch of a brand new search service, you could focus on only using search queries that resulted in users clicking on a result post-query. Don’t neglect your query blacklists, in order to avoid auto-completing potentially-embarrassing or undesirable terms. Weighting by query frequency would be a good starting point.
Previous queries, refined or otherwise, can also be a legitimate source of data for auto-completions, auto-suggestions or auto-refinements. You may also choose to display the detail of those refinements or the number of matching search results last time such a query was performed.
Content Pathways
If you’re using your search engine’s analytics to track refinements or faceted navigation clicks as part of a user’s post-query activities, this information could also be sourced to anticipate common content pathways for auto-refinement. In our Nike example, users may frequently start in ‘all departments’, then refine by 'Department: Men’s Shoes' after searching. This known behaviour can itself become a data source for auto-refinements.
Caveats
Auto-completion, auto-refinement and auto-suggestion are not foolproof, but there are some scenarios where they're unlikely to be useful, and combinations of technologies that may prevent them from being used at all.
In a desktop browser scenario, it’s practically impossible to achieve these types of behaviours on browsers where client-side scripting is unavailable. Ensure you have a non-scripting fallback - server-side query refinement and spelling autocorrection are reasonable approximations of this behaviour.
Judicious use of Accessible Rich Internet Application (ARIA) technologies is also strongly recommended if rolling your own front-end library. This ensures that the dynamically-changing page components are accessible by users solely interacting via a keyboard, or who may be using screen reader software.
Finally, when implementing these interfaces into your HTML5 designs, be sure to disable your browser’s default auto-complete behaviour, which will only source suggestions from that browser’s input history, potentially clashing with your own designs:
…
<input
auto-complete=“off”
required
type="search"
name="query"
id=“query”
size="30"
value=""
placeholder="Search example site..." />
…Tracking Success
With all of those ‘answers’ appearing directly below a search input box, users may never need to click through to a full search results page again. Indeed, no clicking may even be necessary to satisfy a user’s information requirements (I typed ‘jav’: Javinda’s photo, phone number and email address appeared, and I picked up the phone to call her immediately), making traditional click-based success like tracking a slippery beast.
At the very least, ensure you capture the following key metrics for any scenario resulting in a click (or a search submitted after using the keyboard to select a suggestion / completion) to allow for a detailed ongoing analysis:
- Partial query entered (e.g. ‘jav’).
- URL where partial query was entered.
- If auto-completions were used:
- Full term submitted for searching if auto-completion was used (e.g. ‘java’ or ‘javinda’).
- Position of completed term in list.
- If auto-suggestions were used:
- URL of suggested item clicked.
- Position of suggested item in list.
- If auto-refinements were used:
- The scope of the current search was (e.g. ‘All Departments’ or ‘Electronics’).
In the case of an auto-completion or auto-refinement, a user will end up hitting your search results pages - knowing that they’ve got there as part of an interaction with your suggested completions or refinements is also worth tracking at query time as part of your existing search analytics.
Conclusion
Choose the right mechanism, or combination of mechanisms, for the audience, content lifecycle and/or business goals you have in mind:
1. Consider content scope
As the scope of your content narrows or broadens, each method becomes more suitable for your users' search tasks and more technically feasible for your search administrators to maintain.
- Broader > Narrower.
- Auto-Complete > Auto-Refine > Auto-Suggest.
2. Consider content structures
If you have well-structured content types (events, products, people), ensure your auto-suggestions can access the core attributes of those entities at display time.
3. Consider user influence
After a new search system has been launched, you may want to consider including users’ search histories as another data source for auto-completion terms. If enough users are performing successful searches using particular terms, they may be weighted more highly as auto-completion terms, influencing words suggested to other users. Separate to these organic sources, an individual’s query history (along with matching result counts) may also be worth sourcing for a separate tier of suggestions.
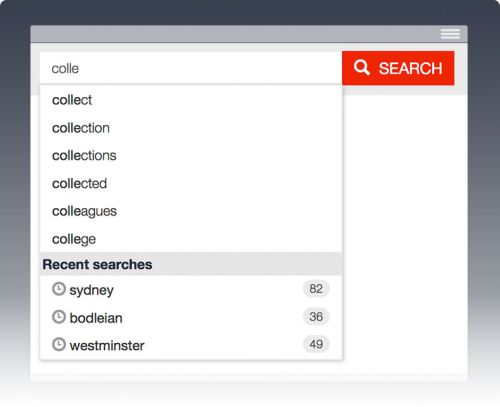
4. Consider device and user context
Hunt-and-peck typists on desktop screens may never see your auto-suggested items, and small-screen devices will put pressure on ensuring the half-dozen items you do suggest are getting them closer to their information destination.
5. Track and refine
Going beyond a CMS or default completion behaviour may take some time and money - get your tracking hooks in early to measure your ROI from this powerful set of user interface behaviours.


